

Local AI: draai Large Language Models veilig op je eigen infrastructuur
Het gebruik van Large Language Models (LLM) zoals ChatGPT is enorm populair geworden sinds OpenAI ChatGPT in november 2022 uitbracht. Sindsdien hebben veel meer bedrijven vergelijkbare LLM’s gelanceerd, zoals Google’s Gemini, Anthropic’s Claude, xAI (Twitter) Grok en meer. Die keuze is prettig voor gebruikers, maar levert voor organisaties ook een grote uitdaging op: data soevereiniteit.
Het is fijn dat er zoveel opties zijn, maar kiezen voor een van deze partijen betekent ook kiezen welke organisatie alle data mag verwerken die je verstuurt wanneer je met hun chatbot werkt. Een provider kiezen betekent vaak: vertrouwen dat zij elk stukje informatie dat je invoert zorgvuldig behandelen. Privé voelt die privacy-afweging bij een losse vraag misschien beperkt. Voor bedrijven liggen de belangen veel hoger. Organisaties moeten een cruciale security vraag stellen: kunnen we het risico nemen dat medewerkers bedrijfseigen broncode, financiële spreadsheets of gevoelige klantdocumenten uploaden naar een cloud van een derde partij?
Gelukkig zijn er manieren om de kracht van LLM’s te benutten zonder allerlei data naar OpenAI en vergelijkbare partijen te sturen. In dit blog laat ik zien hoe je LLM’s lokaal op je laptop/PC of server opzet, en hoe je privé een LLM kunt gebruiken op persoonlijke documenten. Terwijl je nog steeds profiteert van voordelen zoals razendsnelle samenvattingen, creatief brainstormen en geavanceerde datasynthese. Door deze modellen op je eigen hardware te hosten, krijg je de vrijheid om gevoelige datasets, zoals financiële gegevens of private intellectual property, te verwerken zonder de zorgen dat het gebruikt wordt voor training of opgeslagen wordt op een externe server. Het overbrugt daarmee de kloof tussen state-of-the-art intelligentie en compromisloze data soevereiniteit.
Voordat ik inga op de setup en wat je nodig hebt, geef ik eerst wat achtergrond over LLM’s en termen die je online vaak tegenkomt. De installatie zelf is relatief simpel, maar als je je erin verdiept zie je al snel dat er veel varianten zijn: modeltypes, bestandsformaten, parameter-groottes, quantization-methodes, enzovoort.
Model Files
Er is een grote variatie aan publieke LLM-modellen beschikbaar. Een populaire plek om LLM-modellen te vinden is huggingface.com/models. Mensen en bedrijven uploaden daar hun modellen, al is de website niet altijd even intuïtief. Veel tools bieden bovendien een makkelijke manier om modellen te downloaden. Gratis modellen vinden is eenvoudig; een passend model/bestand kiezen vraagt wat meer aandacht. Populaire gratis modellen om te verkennen zijn Phi (Microsoft, kleinere modellen), Qwen (Alibaba), Llama (Meta), Mistral, DeepSeek en Gemma (Google). Probeer vooral een paar populaire modellen en kijk wat goed werkt voor jouw use case.
Bestandstypen
De meeste LLM-modellen die je online vindt zijn een .gguf- of .safetensors-bestand. Dit bestand bevat het complete LLM-model en kan daardoor behoorlijk groot zijn. Zorg dat je een tool gebruikt die een van deze bestandsformaten ondersteunt, anders beperk je je keuze en uiteindelijk ook de bruikbaarheid van je lokale deployment.
De rol van een LLM
Veel LLM’s zijn getraind voor een specifieke rol of use case. Dat zie je vaak terug in de bestandsnaam. Staat er “instruct” in, dan is het model bedoeld voor chat-achtige interactie, zoals ChatGPT. Zie je “text” of geen duidelijke indicatie, dan is het meestal een base model dat vooral bedoeld is om tekst te vervolgen. Je kunt ook termen tegenkomen als “reason(ing)” of een “r”-versie: vergelijkbaar met instruct, maar dan geeft de LLM ook de reasoning-stappen weer die het heeft genomen om tot het antwoord te komen.
Parameter-grootte en quantization
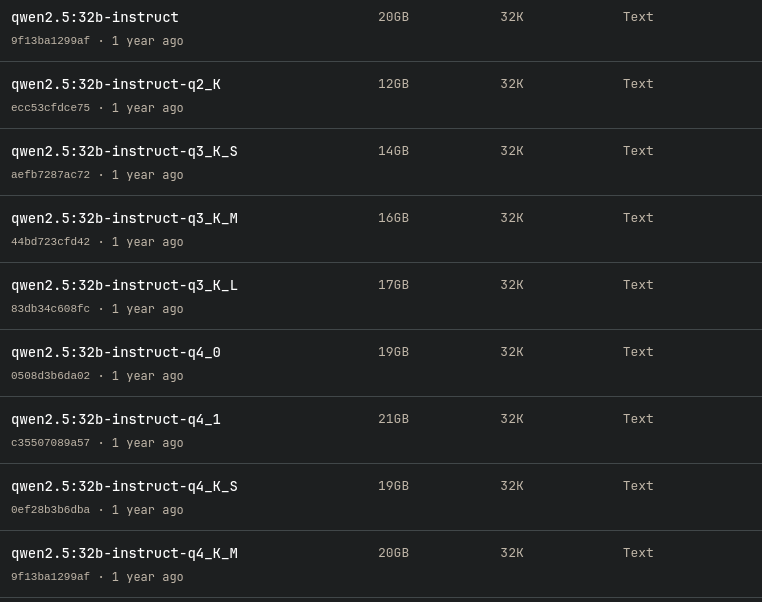
Bij het selecteren van een model zie je vaak meerdere varianten van hetzelfde model. Als je bijvoorbeeld qwen2.5 wilt gebruiken, kun je kiezen uit 0.5b, 1.5b, 3b, 7b, 14b, 32b en 72b. Dit getal staat voor het aantal parameters (b = billion). Hoe groter het aantal, hoe groter het model en doorgaans hoe beter het complexe taken aankan. Maar de bestandsomvang groeit ook sterk, en daarmee de eisen aan RAM/VRAM om het model te kunnen laden. Omdat bestanden zo groot kunnen worden, bestaan er methodes om het model kleiner te maken met zo min mogelijk kwaliteitsverlies: quantization. In de afbeelding hieronder zie je bijvoorbeeld de verschillende quantized varianten van Qwen2.5 32b. Je kiest vaak voor quantization omdat je hardware beperkt is, maar toch meer parameters wilt. Houd er rekening mee dat dit meestal ten koste gaat van kwaliteit. Houd het praktisch: kijk naar de bestandsgrootte en wat past in je geheugen. Daarover straks meer.
Wat heb je nodig?
Je kunt LLM’s draaien op vrijwel elke computer, zelfs op embedded devices zoals een Raspberry Pi of een slimme camera. De performance en de soorten modellen die je dan kunt gebruiken zijn wel beperkt. De twee belangrijkste hardwarecomponenten om rekening mee te houden zijn CPU RAM en GPU VRAM. GPU’s, het meest geschikt voor het draaien/trainen van LLM’s, hebben een beperkte hoeveelheid werkgeheugen. Voor maximale performance (en steeds vaker: om een model überhaupt te kunnen draaien) zijn één of meerdere dedicated GPU(s) nodig, waarbij NVIDIA doorgaans het best wordt ondersteund.
Door de matrixberekeningen die LLM’s vereisen kun je ze ook op CPU’s draaien, maar de performance is dan meestal een stuk lager dan op GPU’s, die geoptimaliseerd zijn voor dit soort berekeningen.
Om te bepalen hoeveel (V)RAM je nodig hebt, kun je grofweg uitgaan van de bestandsgrootte van het model.
Er bestaan tricks om CPU-performance te verbeteren, maar dat valt buiten de scope van dit artikel.
Let op: het is technisch mogelijk om grotere modellen te laden die niet in je RAM passen; het systeem gaat dan swappen naar je SSD/HDD. Dit maakt de LLM echter extreem traag en levert geen prettige ervaring op.
Setup
Voor dit voorbeeld gebruiken we qwen3:8b-q4_K_M. Mijn testsysteem heeft een 12-core CPU en 32GB RAM en draait op Linux, zonder dedicated GPU.
De eerste tool die ik gebruik is Ollama. Ollama is een CLI-interface waarmee je met een LLM kunt interacteren. Het ontsluit de LLM ook via HTTP, waardoor je hem kunt benaderen via curl of via Python en JavaScript. Om Ollama te installeren ga je naar https://ollama.com/download en kies je je besturingssysteem. Na installatie voer je het commando ollama run qwen3:8b-q4_K_M uit. Dit downloadt automatisch het model en start het, waarna je vragen kunt stellen. Klaar.
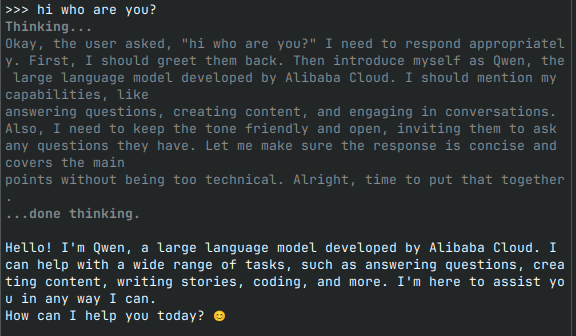
Je hebt nu een volledig werkende LLM die lokaal draait, zonder data naar een datacenter te sturen. In de afbeelding hieronder zie je een voorbeeld waarin qwen3 een thinking model is, dus het reasoned over de stappen die nodig zijn om een antwoord te geven.
Ollama is ideaal om snel een LLM te starten en wanneer je een LLM-agent wilt bouwen in Python of JavaScript. Je kunt het ook combineren met populaire packages zoals Langchain/Langgraph in Python. Ollama ondersteunt ook embeddings (voor documenten), maar daarvoor is wel wat programmeerwerk nodig. Er zijn ook tools met een UI die je een ChatGPT-achtige ervaring in de browser geven.
GPT4ALL
GPT4ALL biedt een UI waarmee je eenvoudig modellen installeert, custom databases maakt met informatie die de LLM kan gebruiken, en een chat interface hebt die het gesprek overzichtelijk toont. Let op: GPT4ALL verzamelt anonieme gebruikersdata, maar je kunt dit uitzetten in de instellingen of het volledig offline draaien. De kracht is dat je eenvoudig lokale documenten kunt uploaden en daarna vragen aan de LLM kunt stellen over die documenten.
Download GPT4ALL via https://www.nomic.ai/gpt4all. Ga na het starten naar chat of models en installeer een model. Het laat zien hoeveel RAM je nodig hebt. In dit voorbeeld koos ik DeepSeek-R1-Distill-Qwen-14B. Daarna ging ik naar het tabblad LocalDocs en maakte ik een eigen document store. Ik selecteerde een folder met 1 pdf: de basic rule set voor Dungeons and Dragons, 115 pagina’s. GPT4ALL maakt dan embeddings, oftewel: het zet woorden uit documenten om naar vectoren zodat de LLM de informatie kan gebruiken in de chat. Afhankelijk van de hoeveelheid en grootte van documenten kan embedding best even duren; dit hangt ook af van je systeem. Standaard embed GPT4ALL alleen bestanden met deze extensies: .docx, .pdf, .txt, .md, .rst. Je kunt meer extensies toevoegen, maar GPT4ALL kan niet garanderen dat het altijd goed werkt.
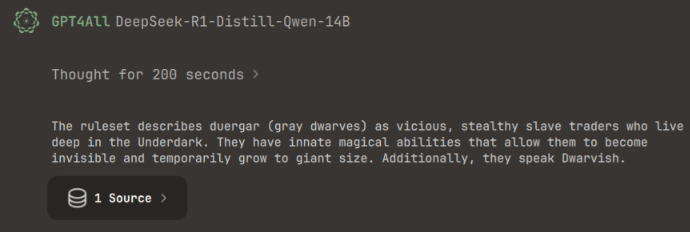
Ga daarna naar Chats, selecteer het model dat je hebt gedownload en kies rechtsboven de LocalDocs die je zojuist hebt aangemaakt. Stel simpelweg een vraag over de documenten en het model zal de documenten gebruiken voor de antwoorden. Dit kan wat traag zijn, dus neem de tijd. Ik vroeg DeepSeek: “What does the ruleset say about Duergar?” Het antwoord is te zien in de afbeelding hieronder en komt overeen met de beschrijving van de Duergar in de ruleset.
Waarom zou je een lokale LLM gebruiken?
Databescherming
Zoals in de introductie gezegd: de kracht van een lokale LLM is dat alle vragen die je stelt en alle documenten die je uploadt binnen je lokale omgeving blijven. Er wordt geen data gedeeld met een datacenter. Het model zelf is bovendien niet in staat om data die je invoert “op te slaan”. Dat betekent dat je volledige controle hebt over je data en veilig vragen kunt stellen over bedrijfseigen broncode of vertrouwelijke documenten.
Dit is ook waardevol voor situaties waarin een systeem air-gapped moet zijn (dus losgekoppeld van het internet). Zowel Ollama als GPT4ALL houden data binnen je lokale netwerk en zijn niet afhankelijk van een internetverbinding.
Kostenbesparing
Door lokaal te draaien voorkom je kosten voor API’s, die bij hoge volumes en constant gebruik snel kunnen oplopen. Je hebt wel initiële investeringskosten en operationele kosten (zoals elektriciteit), maar het maakt niet uit of je 10 tokens of 10 miljoen tokens genereert: je betaalt niet per token. Je gaat van variabele, onvoorspelbare API-kosten naar een vaste investering. Een extra voordeel: betaalde LLM-API’s kennen vaak rate limits op het aantal requests. Dat kan downtime veroorzaken, of extra kosten om je rate limit te verhogen. Lokaal is er geen rate limit op de API; je hardware is de enige beperking.
Zowel Ollama als GPT4ALL kunnen modellen via een eigen API beschikbaar maken. Dat is handig als je al applicaties hebt die LLM’s via een API bevragen. Je verlaagt dan de kosten die je anders maakt door betaalde LLM-API’s te gebruiken.
Latency
Met GPU’s kan de latency van een lokaal gehoste LLM aanzienlijk lager zijn dan bij API calls naar een datacenter. Je praat met een lokaal systeem dat voor jou beschikbaar is, zonder lange netwerkroute en zonder gedeelde resources. Dat verhoogt de responssnelheid.
Trade-offs
Natuurlijk zijn er ook nadelen aan zelf hosten. Je moet het LLM-model beheren, updates bijhouden en soms troubleshooting doen. Dat kost tijd en inspanning en hoort dus bij de TCO. Daarnaast kunnen hardwarekosten (CAPEX) een flinke initiële investering zijn, in plaats van een pay-as-you-go (OPEX) model.
Ollama vraagt iets meer setup maar biedt veel flexibiliteit. GPT4ALL is meer een totaalpakket met UI en maakt documenten uploaden heel eenvoudig, maar met minder flexibiliteit. Wil je medewerkers bijvoorbeeld een ChatGPT-achtige ervaring bieden, maar dan lokaal, dan is GPT4ALL vaak een goede keuze. Heb je applicaties die een generieke interface met een LLM nodig hebben, dan is Ollama logischer omdat het een algemene API biedt waar veel tools mee kunnen werken.
Start vandaag met je Local LLM Journey
De verschuiving naar local AI is een fundamentele verandering in hoe we met technologie omgaan: van ‘data voor services’ naar echte digitale soevereiniteit. Naarmate open-source-modellen de kloof met closed-source-alternatieven blijven verkleinen, wordt het argument voor “je eigen intelligence hosten” steeds sterker. Als je vandaag start met je local LLM journey, bescherm je niet alleen je data; je bouwt ook een private basis voor de toekomst van je digitale workflow. Als je organisatie onderzoekt hoe je AI veilig en verantwoord kunt inzetten, kunnen wij helpen om je opties te beoordelen en een setup te ontwerpen die performance, compliance en lange termijn kosten in balans brengt.



